
In my previous post, I highlighted basic elements of segmentation, data and interventions in the consumer and healthcare space. My goal was to frame a discussion around how to improve SDOH-focused nonclinical interventions by using consumer-focused measures like return on investment (ROI). After all, nonclinical interventions are expensive. Why not target patients who represent the greatest potential for success?
In this post, I’ll highlight another distinction between consumer and healthcare marketing: the difference in how freely information flows, especially in the nonclinical space of healthcare. I point this out because, if you look at consumer marketing, the sheer amount of data and the speed with which it is shared and aggregated allows marketers to target consumers with highly specific personalized marketing campaigns. And the feedback is almost instantaneous. Every time you buy a product or browse the internet, that information is quickly associated with you. This provides marketers the ability to continually refine your highly personalized offers.
Healthcare is a bit different. There are a lot of different layers to how data is shared and used within the healthcare space, especially when it comes to treating chronically ill patients. You have clinical data versus nonclinical data, structured data versus unstructured data and more. Let’s highlight some key differences in the clinical and nonclinical environments and discuss how they impact our ability to create highly personalized nonclinical interventions that impact Social Determinants of Health.
Data moving around
The growth in healthcare data has been astronomical. I’ve covered this in previous posts. I have also written about Social Network theory and a concept called “network density” which is a description of how connections in a communication network allow information to efficiently move through it. Look at the following graphic:
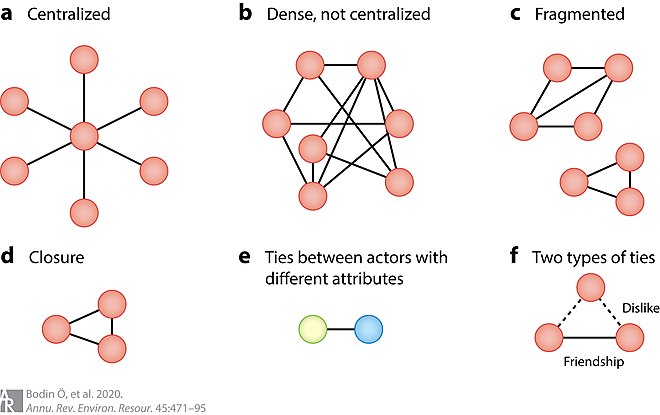
The more connections you have in a network, the higher the potential for efficiently sharing data. This is an important point. If you’re truly interested in effective communication or data sharing within a group or organization, you need to create network density, so data is shared not only efficiently but bidirectionally. Meaning when you share information, you also have an equally efficient manner of capturing feedback on that information. Creating this type of situation gives you a great deal of power in targeting populations or individuals with the right information in the right format at the right time, because the feedback provides the ability to continually refine your client profile.
When you have connections between every potential area in a network, information can move very quickly from point to point. If you have more of a hub and spoke or fragmented network (like you see in the diagram above), information sharing can be inefficient or nonexistent.
The clinical advantage
How does information flow in the healthcare environment? Let’s start with the clinical space.
Most healthcare systems have electronic records systems to capture a wide variety of data about patient interactions. These might include patient/doctor discussions, test data, personal information and more. All this data forms the patient record.
Even more, EHR providers have created population health platforms to support the treatment of chronically ill patient populations. These platforms are effective at aggregating disparate data sources (including clinical, claims and enrollment data) and normalizing them to create a comprehensive or longitudinal patient record. Additionally, powerful analytics tools are built into these platforms that allow healthcare systems to analyze their clinical performance financially, as well as in patient outcomes. This matters because our government provides significant incentives to healthcare systems to lower costs and improve outcomes for high cost chronically ill patients.
But as I’ve mentioned in a previous post, most healthcare systems did not implement these comprehensive platforms until 2010 or so. Since then, there’s been great progress enhancing population health platforms to improve data sharing/aggregation and reporting capabilities.
Nonclinical lags behind
Our government has created a program called Healthy People 2030. The following represents a graphic from this program which highlights six categories of social determinants of health. You can read more at the following link.

This program is comprehensive, exploring a wide variety of nonclinical issues that impact individual health. These programs also target individuals of all ages.
However, my focus with this discussion is solely to target chronically ill patient populations and examine how we can create interventions to address determinants of health in a way that improves outcomes and lowers costs. If you think about this purely from a healthcare intervention standpoint, there are key elements of standard clinical interventions affected by the nonclinical ones. For example, look at the following:
- Transportation. We want patients to go to all their follow up appointments. Maybe we provide transportation.
- Food Insecurity. For many chronic conditions, diet is an important element of treatment. How can we enable access to healthy food?
- Housing Insecurity. Individuals who have trouble paying for housing report far higher rates of poor to fair health and are often forced to delay doctor visits due to cost.
Unfortunately, the ability to integrate these nonclinical elements into a chronic illness intervention is a developing capability. There are SDOH-oriented applications or capabilities being integrated into the population health platforms that healthcare systems use on the clinical side. These provide the capability to connect patients with local organizations to support elements like transportation or food.
More importantly, the nonclinical space is also more fragmented in terms of data movement and coordination. The ability to gather feedback on the success of these interventions is limited. We can certainly define some level of success if we lower claims cost or improve outcomes, but we don’t have as much capability to determine which element of the intervention had the greatest effect. We also don’t have much, if any, capability to determine which patients exhibit the highest Impactability – which is the patient’s likelihood of responding positively to an intervention.
Over the last ten years or so, the clinical space has built up platform capability and network density, efficiently sharing information used to examine performance. But the nonclinical side is behind right now. We can capture and document issues patients face in nonclinical areas of their life (and look to provide some form of intervention), but the ability to capture back information about how well these particular solutions work is limited at best.
Where will we go?
A lot of people and government entities are trying to address SDOH issues. States are creating waiver programs (like CalAIM in California,) looking to provide care management and funding for at risk populations. Vendors are investing heavily in this space to add capability in nonclinical data capture and platform design. The future is bright.
However, I believe we won’t truly achieve success in nonclinical interventions until we improve data gathering to include:
- Individual data on patient impactability/activation.
- Increased network density to speed the bidirectional flow of nonclinical data.
- Tools to provide the ability to build highly personalized nonclinical interventions, find patients with high levels of impactability, and provide feedback on which intervention elements delivered the greatest return in ROI in the form of reduced claims or improved outcomes
In my next post in this series, I’ll go through a thought exercise on a new approach to building and assessing nonclinical interventions.
No Comments